Mise en œuvre de l’Intelligence Artificielle
Quels impacts opérationnels ? Exemples dans l’immobilier.

L’intelligence artificielle investit progressivement tous les secteurs et suscite de nombreuses réactions. Afin de porter un regard plus précis sur les enjeux avérés, il nous semble nécessaire de préciser ce que désigne l’intelligence artificielle puis de détailler les applications et les étapes de mise en œuvre, sur la base d’illustrations dans le secteur immobilier.
Une difficile définition de l’intelligence artificielle
Il est difficile de s’accorder sur une définition de l’intelligence artificielle. En effet, ce terme désigne souvent d’une part, ses champs d’étude : « Machine Learning », « Deep Learning », … et d’autre part, ses applications : reconnaissance vocale, reconnaissance visuelle, analyse prédictive, robotique …
De manière générale, on assimile l’intelligence artificielle à l’ensemble des techniques permettant de doter une machine de capacité de réflexion comparable à celle de l’homme, non limitée à certains domaines ou à certaines tâches.
Le Machine Learning, champ d’étude de l’intelligence artificielle
Le Machine Learning est le champ d’étude de l’intelligence artificielle qui s’est le plus développé récemment. Il désigne un dispositif qui combine des modèles et des algorithmes capables de formuler des réponses structurées, à partir d’un grand volume de données.
On associe une « capacité d’apprentissage » aux dispositifs de Machine Learning car leur performance s'améliore avec le nombre de données qui leur sont fournis. L’apprentissage s’entend au sens où l’exploration des combinaisons est à la fois automatique et plus large que ce que le concepteur a pu imaginer initialement.
La donnée est centrale dans le Machine Learning, ce qui explique son développement récent étant donné que les capacités de collecte de données se sont elles-mêmes grandement amplifiées (big data).
Pour rendre notre approche du Machine Learning plus concrète, nous avons choisi de présenter deux exemples d’applications dans le secteur immobilier.
Le Machine Learning appliqué à la reconnaissance de texte …
Le Machine Learning permet d’analyser le contenu de documents et d’en extraire les données clés, en permettant la reconnaissance de texte et de langage.
Ainsi, il existe des solutions capables d’extraire les données de documents tels qu’un bail. Les données qui vont pouvoir être reconnues sont ainsi : le nom du propriétaire, la date d’échéance, les montants des loyers, les indices permettant l’indexation et la révision, …
Le fonctionnement est d’apprendre à l’algorithme quelles données reconnaître. Plus le nombre de baux qui alimentera la solution sera important, plus la précision des données extraites sera élevée. La solution saura ensuite identifier les données dans des baux qui ne seront pas structurés de la même façon ; ce qui est fréquent pour une direction de l’immobilier ou un administrateur de biens qui ont de grands volumes de baux avec des propriétaires différents.
… ou à la détermination d’une valeur cible.
Le Machine Learning peut aussi être utilisé en tant qu’appui à la prise de décision, en permettant de déterminer une valeur cible. Ainsi, il est possible de recourir au Machine Learning pour déterminer : la valorisation future d’un bien immobilier, la probabilité qu’un client fasse défaut sur un emprunt, qu’un locataire ne paie pas son loyer, etc.
Nous détaillerons ci-après les étapes de mise en œuvre d’un modèle de Machine Learning, ce qui nous permettra de mieux cerner les enjeux opérationnels associés.
La conception du modèle commence par la définition d’une question de recherche, qui consiste à définir le résultat attendu, telle que la valeur estimée d’un bien immobilier, si nous reprenons un des exemples ci-dessus.
Il s’agit ensuite d’identifier les variables qui impactent le résultat attendu. Ainsi, le taux de l’indice, le temps, la zone géographique, etc. vont faire varier la valeur initiale du bien.
A partir des variables identifiées, on va sélectionner les données qui vont permettre au modèle de s’exercer. Ces données sont nommées « population d’apprentissage ». Dans la continuité de notre exemple, il s’agira de sélectionner un ensemble de biens pour lesquels la valeur initiale du bien, les variables et la valeur estimée sont connues.
La création du modèle consiste à ce que l’algorithme « s’exerce » à partir de la population d’apprentissage à produire un résultat qui s’approche le plus possible du résultat attendu (cf. schéma ci-dessous). Il est nécessaire de définir en amont quel est le seuil d’écart ou d’échec toléré par l’algorithme. Dans notre exemple, l’objectif est que le modèle « apprenne » à calculer une valeur estimée la plus proche possible de la valeur estimée connue.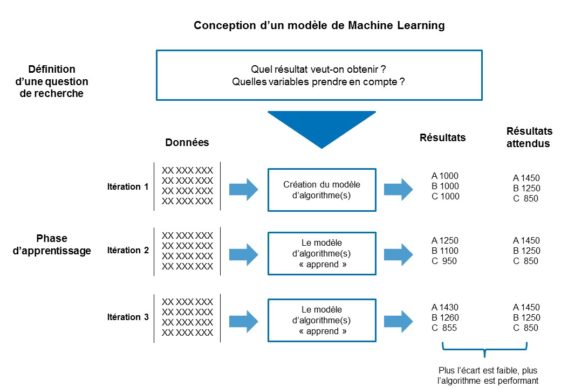
La phase de test consiste ensuite classiquement à tester le modèle. Afin de valider le fonctionnement du modèle, les tests seront réalisés à partir d’une population de données qui n’a pas été utilisée lors de la création.
Ces différentes étapes de mise en œuvre d’un modèle de Machine Learning impliquent d’être pilotées comme pour un projet « classique », si l’on veut éviter certains écueils dans l’aboutissement au résultat.
Les données sont clés ainsi que la pertinence des variables retenues
L’accès à la donnée est crucial et nécessite d’avoir à disposition un volume de données conséquent. Des travaux de préparation des données seront à réaliser, la qualité des données étant un prérequis et nécessitant des étapes de « nettoyage » afin de s’assurer de leur cohérence.
Cette étape nécessitera de recourir aux experts Métier pour s’assurer de la pertinence et de la qualité des données utilisées.
L’opacité dans la production des résultats va nécessiter des contrôles et des tests a posteriori
Un point d’attention est à relever concernant l’utilisation des résultats produits par le modèle. En effet, le fonctionnement des dispositifs d’algorithmes rend la production des résultats peu interprétable et est parfois qualifié d’opaque (on parle aussi de « boîte noire » des algorithmes). Or, c’est bien l’exploitation des résultats par les opérationnels (asset manager, gestionnaires, commerciaux, etc.) qui doit permettre la prise de décision.
Pour contourner cette difficulté, il est possible de mettre à disposition des opérationnels la liste des variables utilisées par le modèle. A défaut de pouvoir expliquer le cheminement de calcul, cela leur permettra de comprendre quels critères sont pris en compte par le modèle et impactent les résultats.
D’autre part, face à ce risque d’opacité, des contrôles seront à mettre en place ainsi que des tests en exploitation, tels que la réalisation de « backtesting » en comparant les résultats obtenus pour la valorisation d’un bien et la valeur réelle lors de la cession.
Ce besoin de compréhension et d’explication induit par la mise en œuvre de modèles de Machine Learning va être un enjeu de gestion du changement pour les entreprises.
La mise en œuvre du Machine Learning va entraîner l’évolution des Métiers
Un des autres enjeux sera, pour les entreprises, de prendre la mesure des impacts de la mise en œuvre du Machine Learning sur les métiers de ses collaborateurs puis d’accompagner les dits collaborateurs dans leur évolution.
En effet, il ne s’agira plus de produire un résultat (valoriser un bien, estimer la probabilité de défaut, …) mais d’adosser aux résultats obtenus une analyse pertinente permettant la prise de décision. La dimension relationnelle des métiers va ainsi prendre de l'ampleur. Ainsi, un gestionnaire passera moins de temps à collecter des informations pour évaluer un bien et davantage à conseiller son client.
A l’heure actuelle, il apparaît certain que les entreprises qui collectent ou qui génèrent beaucoup de données vont se lancer dans la conception de leur propre modèle de Machine Learning pour fournir un service prédictif (cf. l’étude Akeance Consulting : « L’immobilier à l’aube du big data » qui présente un ensemble de solutions intégrant le Machine Learning).
Le succès de ces applications de l’intelligence artificielle sera conditionné par un travail de pédagogie en interne, tant d’explication sur le fonctionnement du modèle, que de précision dans sa conception et d’accompagnement dans l’évolution des missions et métiers des collaborateurs.